Example: Working on Biase¶
Install GraphHDBSCAN package
Install dependency:
!pip install git+https://github.com/Campello-Lab/GraphHDBSCAN.git
from coresg_graphhdbscan import GraphCoreSGHDBSCAN
/usr/local/lib/python3.12/dist-packages/hdbscan/robust_single_linkage_.py:175: SyntaxWarning: invalid escape sequence '\{'
$max \{ core_k(a), core_k(b), 1/\alpha d(a,b) \}$.
Load Data
import yaml
import scanpy as sc
# Load the YAML configuration file
with open("config.yaml", "r") as f:
config = yaml.safe_load(f)
Biase_config = config["DATASETS"]["Biase"]
expected_cell_label = Biase_config["cell_labels"]
# Load the AnnData object
adata = sc.read_h5ad("/content/Biase.h5ad")
# Print available columns in adata.obs
available_columns = list(adata.obs.columns)
print("Available columns in adata.obs:", available_columns)
cell_label_key = expected_cell_label
# Extract the count matrix and cell labels
count_matrix = adata.X # Cells as rows and genes as columns
true_labels = adata.obs[cell_label_key]
Available columns in adata.obs: ['cell_type', 'n_genes']
Clustering
g = GraphCoreSGHDBSCAN(
min_samples=range(2,30),
sim_graph_method="sc_gauss",
n_neighbors=5,
no_noise=True,
metric="cosine",
)
g.fit(adata.X)
[CORE-SG] (precomputed) CORE-SG graph has 1176 edges
[CORE-SG] m= 2: MST+tree+labels in 0.0116s
[CORE-SG] m= 3: MST+tree+labels in 0.0178s
[CORE-SG] m= 4: MST+tree+labels in 0.0042s
[CORE-SG] m= 5: MST+tree+labels in 0.0036s
[CORE-SG] m= 6: MST+tree+labels in 0.0034s
[CORE-SG] m= 7: MST+tree+labels in 0.0036s
[CORE-SG] m= 8: MST+tree+labels in 0.0034s
[CORE-SG] m= 9: MST+tree+labels in 0.0031s
[CORE-SG] m=10: MST+tree+labels in 0.0032s
[CORE-SG] m=11: MST+tree+labels in 0.0031s
[CORE-SG] m=12: MST+tree+labels in 0.0032s
[CORE-SG] m=13: MST+tree+labels in 0.0032s
[CORE-SG] m=14: MST+tree+labels in 0.0061s
[CORE-SG] m=15: MST+tree+labels in 0.0051s
[CORE-SG] m=16: MST+tree+labels in 0.0040s
[CORE-SG] m=17: MST+tree+labels in 0.0031s
[CORE-SG] m=18: MST+tree+labels in 0.0031s
[CORE-SG] m=19: MST+tree+labels in 0.0040s
[CORE-SG] m=20: MST+tree+labels in 0.0032s
[CORE-SG] m=21: MST+tree+labels in 0.0034s
[CORE-SG] m=22: MST+tree+labels in 0.0033s
[CORE-SG] m=23: MST+tree+labels in 0.0030s
[CORE-SG] m=24: MST+tree+labels in 0.0032s
[CORE-SG] m=25: MST+tree+labels in 0.0029s
[CORE-SG] m=26: MST+tree+labels in 0.0032s
[CORE-SG] m=27: MST+tree+labels in 0.0032s
[CORE-SG] m=28: MST+tree+labels in 0.0031s
[CORE-SG] m=29: MST+tree+labels in 0.0030s
GraphCoreSGHDBSCAN(min_samples_list=[2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29], metric='cosine', eps=1e-12, min_cluster_size=None, X_=None, N_=None, D_=None, core_={}, kmax_=None, edges_ut_=None, idx_with_self_=None, dst_with_self_=None, idx_no_self_=None, dst_no_self_=None, A_knn_=None, msts_={}, mst_times_={}, models_={}, times_={})
Intractable condensed tree
g.interactive_condensed_tree()
Labels for min_samples = 6
labels_ = g.labels_for(6)
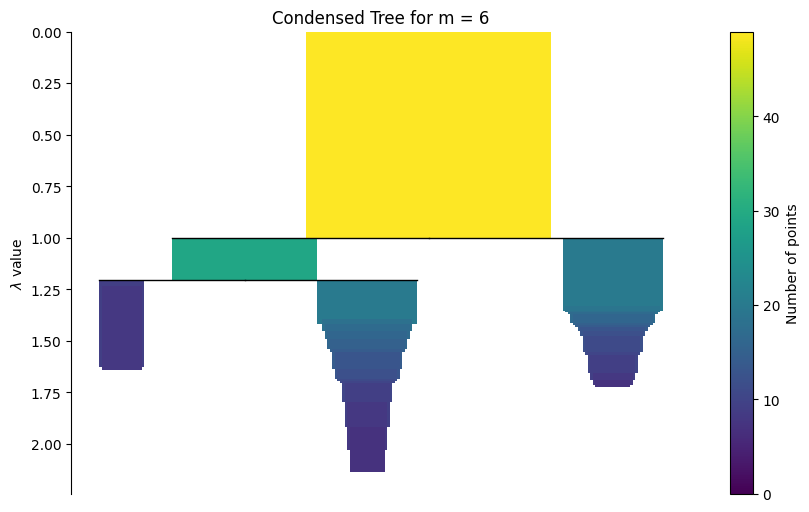
Condensed tree for min_samples = 6
g.plot_condensed_tree(6)
<Axes: title={'center': 'Condensed Tree for m = 6'}, ylabel='$\\lambda$ value'>
Evaluation
Install dependency:
!pip install genieclust
import numpy as np
import pandas as pd
import scanpy as sc
from sklearn.metrics import adjusted_mutual_info_score, adjusted_rand_score
from sklearn.preprocessing import LabelEncoder
# Import the pair_sets_index function as PSI from genieclust.compare_partitions
from genieclust.compare_partitions import pair_sets_index as PSI
def evaluate_clustering(true_labels, predicted_labels):
"""
Compute Adjusted Mutual Information (NMI), Adjusted Rand Index (ARI),
and Pair Set Index (PSI) between true and predicted cluster labels.
Since PSI (pair set index) expects numeric labels, we convert the input
labels from strings (if necessary) to integers using LabelEncoder.
"""
# Compute AMI and ARI directly; these metrics accept string labels.
ami = adjusted_mutual_info_score(true_labels, predicted_labels)
ari = adjusted_rand_score(true_labels, predicted_labels)
# Use a single LabelEncoder fitted on the union of all labels to ensure consistent encoding.
all_labels = list(set(true_labels) | set(predicted_labels))
encoder = LabelEncoder()
encoder.fit(all_labels)
# Transform true and predicted labels into numeric values.
true_labels_numeric = encoder.transform(true_labels)
predicted_labels_numeric = encoder.transform(predicted_labels)
# Calculate the Pair Set Index (PSI) using the numeric labels.
psi = PSI(true_labels_numeric, predicted_labels_numeric)
return ami, ari, psi
ami, ari, psi = evaluate_clustering(true_labels, labels_)
print("Precomputed matrix mode:")
print("AMI:", ami)
print("ARI:", ari)
print("PSI:", psi)
Precomputed matrix mode:
AMI: 1.0
ARI: 1.0
PSI: 1.0